診療ガイドライン・システマティックレビュー
の読み方 ガイド
本サイトは作成者向けのGRADEハンドブックとは別に、読み手の視点で「どこを見るか・どう判断するか・どう現場に持ち込むか」に特化しています。
公益財団法人日本医療機能評価機構 🔬Cochrane Library(日本語)
世界標準のSRアーカイブ 🇬🇧NICE Guidance(英国)
国際的に参照されるCPG 📊GRADE Working Group
方法論の最新情報
EBMと診療ガイドライン・SRの読み方
Gordon Guyatt 先生らが編集する JAMA Users' Guides to the Medical Literature は、個別の論文タイプ(RCT、SR、診断研究、CPG など)ごとに「臨床家が読むときに自問すべき質問」を体系化した標準テキストです。本章で扱う SR/CPG の読み方は、同書 Ch22〜Ch26 に対応します。
- SR/MA プロセスの見抜き方 → JAMA UG Ch22 要約ページ
- 結果の理解と患者への適用 → JAMA UG Ch23 要約ページ
- 直接比較がない選択肢の比較(NMA) → JAMA UG Ch24 要約ページ
EBMの25年間の進化
EBMは1990年代初頭、RCTをエビデンスピラミッドの頂点に置く階層モデルから出発しました。以降、Djulbegovic & Guyatt [G1] が総括した通り、EBMは以下のような成熟を遂げました:
- SRが第一情報源に:個別RCTよりも系統的レビュー+メタ解析が臨床判断の基盤となった
- エビデンスの「確実性」という概念の導入:単なる研究デザインではなく、バイアスリスク・一貫性・直接性・精度・出版バイアスで総合評価するGRADEが普及
- 観察研究の再評価:RCTが実施困難な場合の観察研究の活用方法が整備された [G2]
- 患者の価値観と嗜好の組込み:推奨の強さ決定に「価値観」が明示的要素として組み込まれた
- 共同意思決定(SDM):特に条件付き推奨では患者との対話が必須との理解が定着
診療ガイドライン(CPG)とシステマティックレビュー(SR)の関係
臨床家が実際に日々参照するのは、生のRCTではなく:
- システマティックレビュー(SR):特定の臨床疑問について、系統的に文献を検索・選択・評価・統合した二次研究。メタ解析(統計的統合)を含むこともある。[U12]
- 診療ガイドライン(CPG):複数のSRの結果をパネル討議で推奨に変換したもの。推奨の方向(賛成/反対)と強さ(強い/条件付き)、根拠となるエビデンスの確実性を提示する。[U16]
読み手としての3つの問い
🎯 SRやCPGを読むとき、常に自問する3つ
- このエビデンス(あるいは推奨)は妥当か?(=信頼できるか)
- 結果は何か?(=効果の方向と大きさ、確実性)
- 自分の患者に適用できるか?(=Applicability)
これが Users' Guides to the Medical Literature [U18] の30年来の基本枠組みです。本サイトの各章はこの3つの問いに沿って構成されています。
本サイトの読み進め方
初めての方は Ch2(GRADE概要)→ Ch3(確実性)→ Ch4(推奨強度)→ Ch5(SoF表)→ Ch16(信頼できるCPG)の順がおすすめ。すぐに判定ツールを使いたい方は Ch16の6質問チェックリストから始めてください。
🗺️ 診療ガイドライン/SRの文書構造マップ — 「どこに何が書いてあるか」の全体像
本サイトで学ぶGRADE・MID・RoB・AMSTAR 2などの各トピックは、すべて実際のCPG/SR文書の「どこかの一節」を読み解くためのものです。下のマップは、CPGとSRの典型的な章立てを示し、各セクションに書かれている内容とそれを読むために必要な本サイトの章を対応させています。各章を読んでいる最中に「今どこを読もうとしているか」分からなくなったら、いつでもここに戻ってください。
📖 文書構造ナビゲーター
タブを切り替えて、診療ガイドライン(CPG)とシステマティックレビュー(SR)それぞれの典型的な構造を確認してください。各セクションの「🎓 学習章」ボタンをクリックすると、そのセクションを読むのに必要な章へ直接ジャンプします。
1
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
10
11
12
13
GRADEアプローチの概要 — なぜ最初に学ぶのか
🧭 なぜCPG/SRの読み方を学ぶ初心者が、まず「GRADE」から学ぶのか?
"GRADE" という耳慣れない用語が急に出てきて混乱するかもしれません。でも大丈夫。この用語を避けて通ると、CPG/SRのほぼすべての内容が理解できなくなるからです。理由は3つあります:
- 現代のCPG/SRの「共通言語」だから — 世界110以上のガイドライン組織(WHO、NICE、Cochrane、Minds、米国内科学会…)がGRADEを採用 [U13]。「エビデンスの確実性:中」「条件付き推奨」「⊕⊕⊕◯」などの記号と用語はすべてGRADEの産物です。GRADEを知らずにCPGを読むのは、文法を知らずに外国語を読むのと同じです。
- 本サイトの全24章の地図になるから — Ch3は「確実性4段階」、Ch4は「推奨の強さ」、Ch5-7はGRADEの具体的な表現、Ch8-12はGRADEの「確実性を下げる5要因」の詳細、Ch16-19は「GRADEが正しく適用されたかを評価する」ツール…すべての章がGRADEの一部分を掘り下げる形で構成されています。
- あなたの臨床判断を変えるから — GRADEは「何をどのくらい信じて、どのくらい患者に勧めるか」を構造化する道具です。「この治療は強く推奨されている」と「条件付きで推奨されている」で、実臨床でのあなたの行動は明確に変わるべきで、GRADEはその変え方を教えてくれます。
この章のゴール:GRADEという用語の正体を知り、CPG/SRを読んだときに「いま自分はGRADEのどの部分を見ているのか」が分かるようになること。細部の理解はあとで大丈夫です。
GRADEという単語の意味を分解する
「GRADE」は頭字語(acronym)です。1文字ずつ分解すると、この枠組みが何をする道具なのかが見えてきます:
🔤 G・R・A・D・E を分解
つまり直訳すると「推奨を等級付けし、その評価・開発・判定を行う枠組み」。短く言えば「エビデンスと推奨に『格付け』を与える標準ルール」です。GRADEの中核は「格付けを客観的・透明・再現可能に行う」ことにあります。
GRADE以前の世界 — なぜ新しい枠組みが必要だったか
2000年以前、多くの学会は独自のエビデンス分類(Level I, II, III…やA, B, C…)を使っていました。しかし問題がありました:
- 学会ごとに定義がバラバラ — ある学会の「Level B」が別の学会では「Grade II」。読み手は毎回定義表を確認する必要がありました。
- 研究デザインに過度に依存 — 「RCTなら高、観察研究なら低」という単純な階層。しかし質の低いRCTと優れた観察研究ではどちらが信頼できるかは単純に決まりません。
- エビデンスと推奨の混同 — 「エビデンスの質」と「推奨の強さ」が区別されておらず、「強い推奨=質の高いエビデンス」と誤解されがちでした。
GRADEはこれらの問題を解決するために誕生し、エビデンスの確実性と推奨の強さを完全に分離し、5要因による透明な評価を導入しました。これは25年間のEBM進化の中核成果です [G1]。
GRADEの基本構造 — 2つの独立した判断
GRADEの最も重要な考え方は、以下の2つの判断を絶対に混同しないことです:
- エビデンスの確実性(Certainty of Evidence)(高/中/低/非常に低い、4段階) — エビデンスそのものがどのくらい信頼できるかの評価(Ch3で詳述)
- 推奨の強さ(Strength of Recommendation)(強い/条件付き、2段階) — 推奨を出すかどうか・どの程度強く出すかの判断(Ch4で詳述)
これらは必ずしも一致しません。具体例で見ましょう:
例2:低い確実性だが強い推奨:重篤な感染症の抗菌薬使用について観察研究のエビデンスしかなく確実性は「低」。しかし未治療で死亡率が高く、代替策もない → 強い推奨(Ch4で詳述する例外条件に該当)。
この「エビデンスの確実性と推奨の強さが独立している」という点は、GRADE以前のシステムとの最大の違いであり、読み手として最も誤解しやすい部分です。
エビデンスの確実性を決める5要因(下げる要因)
RCT(ランダム化比較試験)のエビデンスはGRADEでは「高(⊕⊕⊕⊕)」から出発します。そこから以下の5要因のそれぞれについて「深刻な問題がある」と判定されれば確実性を1段下げ、「非常に深刻」なら2段下げます:
| 要因 | 何を見るか | 詳細章 |
|---|---|---|
| ① Risk of Bias バイアスリスク |
個別研究の方法論的欠陥(無作為化、盲検化、脱落、選択的報告) | Ch8 |
| ② Inconsistency 不一致性 |
研究間で結果がバラバラか(説明できない異質性) | Ch9 |
| ③ Indirectness 非直接性 |
PICO(対象・介入・比較・アウトカム)のズレ、サロゲート使用 | Ch10 |
| ④ Imprecision 不確実性(精度不足) |
信頼区間が広く、臨床判断がぶれるか | Ch11 |
| ⑤ Dissemination bias 発表バイアス |
肯定的結果が選択的に発表されている疑い | Ch12 |
この5要因は、CPGのEvidence Profile付録やSRの「Certainty Assessment」の列に必ず記載されています。例えば "serious imprecision due to wide CI"(CIが広く精度不足があるため1段下げ)といった文言。この章から先の Ch8-12 では、各要因について「どういう状況で下げるのか」「読み手として何をチェックすべきか」を個別に掘り下げます。
観察研究を格上げする3条件(上げる要因)
観察研究(コホート、症例対照)は交絡の問題があるため、GRADEでは「低(⊕⊕◯◯)」から出発します。しかし以下の条件を満たせば確実性を上げることができます:
- 大きな効果量(例:RR>2 または <0.5)→ +1段
- 非常に大きな効果量(RR>5 または <0.2)→ +2段
- 用量反応関係が明確 → +1段
- すべての残存交絡が観察効果を弱める方向(つまり真の効果はより大きいはず)→ +1段
古典例:喫煙と肺がんの関連はRR>10で観察研究ベースでも確実性は「高」と評価されます。
推奨の強さを決める判断要素
推奨の強さは、エビデンスの確実性だけでは決まりません。以下の要素を総合的に検討します(EtDフレームワークで構造化)[U16]:
- 望ましい効果と望ましくない効果のバランス(benefit vs harm)
- エビデンスの確実性(高いほど強い推奨を出しやすい)
- 患者の価値観と嗜好の多様性(多様なら条件付き寄りに)
- 資源・費用(費用対効果)
- 公平性(Equity)への影響
- 実施可能性(Feasibility)と受容性(Acceptability)
これらをEvidence to Decision(EtD)フレームワークで構造化して検討します [U16]。CPGの付録に EtD テーブルが掲載されていれば、パネルが推奨の強さをどう決めたかを読み手も追跡できます。
GRADEの「成果物」 — CPG/SRにはこう現れる
GRADEに基づくCPGやSRには、以下の3つの「成果物」が必ず含まれます。これらは Ch1 の文書構造マップの STEP 4-7(CPG)/STEP 10(SR) に該当します:
| 成果物 | 内容 | 詳細章 |
|---|---|---|
| Summary of Findings(SoF)表 | アウトカムごとの相対効果・絶対効果(per 1000)・確実性(⊕⊕⊕⊕等)・平易な要約 | Ch5 |
| Evidence Profile(EP) | SoF表に5要因の判定詳細を加えた完全版。通常は付録に掲載 | Ch5 |
| 推奨とその解釈 | 「強く推奨する(We recommend)」「提案する(We suggest)」の文言と、強さの実務的意味 | Ch4 |
CPG/SRを開いたとき、この3つを探す癖をつけてください。「SoF表がない/Evidence Profileが見当たらない/推奨の強さが明示されていない」CPGは、信頼性に疑問があるサインです(Ch5, Ch16で詳述)。
GRADEを採用しているCPGかを判別する方法
CPG本文を読むとき、以下のキーワードが出てくれば「GRADEベース」と判断できます:
🔍 GRADE採用CPGの見分けサイン
- 方法論セクションに「GRADE approach」「GRADEpro GDT」「Evidence Profile」「EtD framework」の言及
- 確実性表記に ⊕⊕⊕⊕/⊕⊕⊕◯/⊕⊕◯◯/⊕◯◯◯(または High / Moderate / Low / Very Low)
- 推奨文が「We recommend(強い)」「We suggest(条件付き)」の二択
- 推奨の動詞が results in / likely / may / very uncertain に対応して確実性と連動 [G5]
逆に、Level I/II/III や Grade A/B/C などの古い分類しか使っていないCPGは、GRADE非採用の可能性が高いです。この場合は Ch16 の「信頼できるCPGの6質問」で慎重に評価する必要があります。
🛤 この章の先に学ぶこと(学習ロードマップ)
本章で登場した各要素を、以降の章でひとつずつ深く掘り下げます。カードをクリックで各章へジャンプ:
「エビデンスの確実性」4段階の意味
4段階の解釈 — 読み手の視点
| ラベル | 意味(読み手向け) | 推定値への姿勢 |
|---|---|---|
| 高(⊕⊕⊕⊕) | 真の効果は推定値に非常に近い | 基本的に信じて行動してよい |
| 中(⊕⊕⊕◯) | 真の効果は推定値に近いと思われるが、実質的に異なる可能性もある | 推定値を参考に、患者の状況を加味 |
| 低(⊕⊕◯◯) | 真の効果は推定値と実質的に異なる可能性がある | 推定値は参考程度、他の情報と総合 |
| 非常に低い(⊕◯◯◯) | 真の効果は推定値と実質的に異なる可能性が非常に高い | 推定値に依存しない判断を検討 |
読み手が最も注意すべきこと
確実性が高くても効果が小さいこと、確実性が低くても効果が大きいことはあります。確実性は "効果量をどの程度信じられるか" の指標であり、"効果が大きい/小さい" とは別次元です。
確実性は「どこに対して」評価されているか
重要なポイントとして、確実性の評価はアウトカムごとに行われます。例えば「死亡:高」「QOL:中」「有害事象:低」のように、1つのCPG推奨の中で複数の確実性レベルが併記されるのが普通です。
SoF表(Ch5)を読むときは、各アウトカム行の確実性を個別に確認してください。
確実性を上げる・下げる要因
詳細はCh8-12で扱いますが、概観:
- 下げる要因(-1 or -2):バイアスリスク/不一致性/非直接性/不確実性/Dissemination bias
- 上げる要因(観察研究のみ、+1 or +2):大きな効果量/用量反応関係/すべての交絡が逆方向
強い推奨 vs 条件付き推奨 + GPS・推奨表現
強い推奨 vs 条件付き推奨の解釈
| 強い推奨 | 条件付き推奨 | |
|---|---|---|
| 患者にとって | ほぼ全員が選ぶ | 多数派は選ぶが、価値観により選ばない人もいる |
| 臨床家にとって | 例外なく適用してよい | 価値観を確認し、共同意思決定(SDM)が必要 |
| 政策担当者にとって | 標準ケアとして採用可能 | 議論を経て採用、アウトカム測定を |
低い確実性で強い推奨は「レッドフラッグ」
Guyatt 2023 [U17] は、低い確実性のエビデンスで強い推奨を出すことは、原則として疑わしいと明言しています。例外として許されるのは:
- 生命を脅かす状況
- 利益不確実・害確実(→推奨しない)
- 利益が等価で片方がより害少/安価
- 壊滅的な害の可能性
これらに該当しないのに低確実性+強い推奨が出ているCPGは、信頼性に疑問があります。
Good Practice Statement(GPS)
GPS [G4] は、形式的なエビデンスレビューなしに作られる推奨です。例:
- 「患者に情報を十分に提供する」
- 「手洗いをする」
- 「患者の意向を確認する」
GPSは、利益が明らかで代替案が非倫理的・非合理な場合に限って使われます。頻繁にGPSを使うガイドラインは要注意(エビデンスを探す努力が足りない可能性)。
推奨表現の標準化(Piggott 2022)
Piggott et al. [G5] は、EtDフレームワークと推奨の表現を標準化しました。確実性レベルと効果の大きさごとに使うべき動詞・副詞が決まっています:
| 確実性 | 表現例 |
|---|---|
| 高 | 「results in / 〜をもたらす」「reduces / 減らす」(断定) |
| 中 | 「likely results in / おそらく〜をもたらす」「probably reduces / おそらく減らす」 |
| 低 | 「may result in / 〜をもたらすかもしれない」 |
| 非常に低い | 「evidence is very uncertain / エビデンスは極めて不確か」 |
読み手はこれらの表現の強さから、確実性レベルを逆引きできます。
単一推定値がない場合(Murad 2017)
メタ解析で統合できない場合(効果量がばらばら、研究デザインが多様、など)にも、GRADEの5要因は評価できます [G6]。読み手は「なぜ単一推定値がないのか」を見て、その推奨の限界を理解しましょう。
SoF表・Evidence Profileの読み方
SoF表の典型的な列構成
| アウトカム | 相対効果 (95% CI) |
対照群 (per 1000) |
介入群 (per 1000) |
絶対差 (per 1000, 95% CI) |
確実性 | 平易な要約 |
|---|---|---|---|---|---|---|
| 死亡(30日) | RR 0.83 (0.75-0.92) |
130 | 110 | 20 fewer (30-8 fewer) |
⊕⊕⊕⊕ 高 |
治療により死亡が減少する |
※ 上記は Guyatt 2023 [U17] Fig.1 のWHO COVID-19バリシチニブ例を参考に簡略化したもの。
読み手として必ず見る5ポイント
📌 SoF表の読解5ステップ
- アウトカムの重要度を確認:死亡・主要イベントが含まれているか。サロゲートのみなら要注意
- 絶対効果(Absolute)に注目:相対効果は印象を誇張しやすい(Ch6で詳述)
- 絶対差の信頼区間が閾値を超えているか:MID(Ch7)未満なら「実質差なし」
- 確実性ラベル:高/中なら信じる、低/非常に低いなら他の情報と総合
- 平易な要約の動詞:「results in」→高、「likely」→中、「may」→低、「very uncertain」→非常に低い([G5])
Evidence Profile(EP)との違い
EPはSoF表に確実性を下げた理由の詳細("serious indirectness due to use of surrogate outcome"など)を追加したもの。CPG本文にはSoFのみ、付録にEPが載ることが多い。理由を詳しく知りたい場合はEPを確認してください。
SoF表がない/貧弱なガイドラインは疑う
相対効果と絶対効果の違い
違いの数値例
ベースライン100/1000の場合:
100 → 50 人/1000、絶対差 = 50 人/1000 = 20人を治療すれば1人の悪化を防ぐ(NNT=20)
ベースライン10/1000の場合:
10 → 5 人/1000、絶対差 = 5 人/1000 = 200人治療で1人改善(NNT=200)
同じRR 0.5でも、患者への意味はベースラインリスクで大きく異なる
読み手が陥りやすい罠
ベースラインリスクが低ければ絶対差はわずか。1000人で1人が2人になる(「RR 2、二倍のリスク」)状況と、1000人で100人が200人になる状況は、同じ相対表現でも全く違います。
ベースラインリスクをどう推定するか
SoF表では多くの場合、以下のいずれかが用いられます:
- 対照群イベント率:メタ解析に含まれた研究の対照群のイベント率
- 低/中/高リスク集団の想定:ガイドラインが複数のリスク層に対し絶対効果を提示
- 臨床家が自分の患者のリスクを推定して代入:NNT/NNHが実際の臨床に近づく
最良のCPGは、読み手が自分の患者のベースラインリスクに合わせて絶対効果を計算できる情報を提供します(Guyatt LinkedIn post on baseline risk vs effect modification)。
絶対効果差のための方法論(2023)
[M5](絶対リスク差のための論文2023)は、観察研究メタ解析でオッズ比から絶対効果差を導出する標準的な手順を示しています。観察研究のSR(Ch13)を読む際は、絶対効果への変換が適切に行われているかを確認しましょう。
閾値とMID — 臨床的に重要な差とは何か
なぜMIDが必要か
統計的有意差(p<0.05)は、臨床的に意味のある差とは限りません。1000人で0.5人が0.6人になる効果はp値が有意でも臨床的に無意味。逆に、p値が有意でなくても信頼区間の上限が十分大きければ臨床的に重要な可能性があります。MIDはこの臨床的重要性の基準線です。
些細・中・大の3段階閾値
現代GRADEでは、効果量を以下4段階で分類します [M2][M6]:
MIDとImprecisionの関係
信頼区間がMIDをどう含むかで、確実性を下げるかが決まります:
- 信頼区間がMIDを超えていない("no clinically important difference")→ 「small」または「trivial」
- 信頼区間がMIDをまたぐ → 精度不足(Imprecision)で確実性を1段下げる
- 信頼区間が完全にMIDを超えている → 精度は十分(Ch11で詳述)
MIDの推定方法
- アンカーベース法:患者自身が「少し良くなった/変わらない」と評価したスコア差の中央値。最も信頼性が高い。
- 分布ベース法:0.5 SD、0.5 SEM など。二次的指標。
- 合意ベース法:パネル議論で決定。多くのGLで用いられる。
[M7](BMJ 2025)は、アンカーベースMID推定値の信頼性を評価する新instrumentを提供しています。SoF表のMIDがどの方法で設定されたかを確認しましょう。
慢性腰痛のVAS 15mmと、術後痛のVAS 15mmでは臨床的意味が違う。同じ指標でも疾患・状況によりMIDが変わることに注意。
Risk of Bias — RCT + 観察研究(ROBINS-E/I)
同じ研究でも、客観的アウトカム(死亡・画像所見)は盲検化の破綻に比較的頑健、主観的アウトカム(疼痛・QOL・患者報告)はバイアスを受けやすい。したがってアウトカム行ごとに確実性を下げるかを判断します。JAMA UG Ch22 の「バイアスリスクが低い結果をもたらす可能性が最も高い論文を選ぶためのガイド」と同趣旨。
詳細要約は JAMA UG Ch22 ページ。
RCTのRoB 2 — 5ドメイン
- 無作為化プロセス:割付隠蔽・背景バランス
- 介入からの逸脱:プロトコル違反・アドヒアランス
- アウトカムデータの欠損:脱落率・理由の記録
- アウトカム測定:盲検化・測定の客観性
- 報告される結果の選択:事前登録との一致
観察研究のROBINS-E(曝露)/ROBINS-I(介入) — 7ドメイン
観察研究には交絡という固有の問題があるため、より厳密な評価が必要です:
- 交絡(Confounding)
- 参加者選択
- 曝露/介入の測定
- 意図した曝露/介入からの逸脱
- 欠損データ
- アウトカム測定
- 報告の選択
観察研究は交絡の管理(多変量調整、傾向スコア、操作変数など)が十分かが最重要です [G2]。
読み手としてのチェック
📌 バイアスリスクを読むときのポイント
- SRが「RoB評価を実施したか」を確認(AMSTAR 2 Q9)
- 高リスクの研究が多い → 確実性を1-2段下げる根拠になる
- 感度分析(高リスク研究を除いた解析)で結果が変わるか
- 「どの方向に歪んでいる可能性が高いか」の考察があるか
Guyattの警告:早期中止RCT
LinkedIn投稿("Stopping trials early for benefit")で指摘されるように、利益を理由に早期中止されたRCTは治療効果を過大評価しやすい。バイアスリスク評価では「早期中止の有無」も確認すべき対象です。
不一致性(Inconsistency)
- 視覚的評価:フォレストプロット上で点推定値と CI の重なりを目視。「一見して似ているか」が出発点。
- 統計的検定:Q 検定(p 値)、I² 統計量(%)。I² 50% 以上は実質的異質性の候補。
- 事前仮説に基づくサブグループ解析:ばらつきの原因を「患者・介入量・追跡期間・研究の質」で説明。事後の探索は仮説生成に留める。
詳細要約は JAMA UG Ch23 ページ。
読み手が確認する4つの異質性指標
- 点推定値のばらつき:研究ごとの効果が正負逆になっていないか(森林プロットで目視)
- 信頼区間の重なり:各研究の95% CIがどの程度重なっているか
- I² 統計量:0-25%低、25-50%中、50-75%高、>75%顕著な異質性
- p値 for heterogeneity:<0.10で異質性ありとみなすことが多い
異質性が説明できる場合は下げない
サブグループ解析(疾患重症度・年齢・介入量など)で異質性が説明できれば、確実性は下げずに別々の推定値を提示するのが理想。説明できない場合のみ「Inconsistency」で確実性を下げます。
森林プロットの読み方
📌 森林プロット5秒チェック
- 各研究の四角(効果量)が左右バラバラに散らばっていないか
- 統合結果(ダイヤモンド)の幅が広すぎないか
- 外れ値(outlier)があれば、なぜそうなのかの考察があるか
非直接性(Indirectness)
- 患者:目の前の患者が研究対象からかけ離れていないか
- 介入:用量・投与経路・実施環境の差
- 対照:プラセボ対照か、通常診療対照か — 解釈が変わる
- アウトカム:真のアウトカムか、代理アウトカム(サロゲート)か
JAMA UG Ch23 の「結果を自分の患者に直接適用できるか」節を参照 → Ch23 要約ページ
4つの非直接性
- 対象集団の非直接性:研究対象が自分の患者と異なる(年齢、疾患重症度、併存疾患)
- 介入の非直接性:用量・投与方法・デバイスが異なる
- 比較対照の非直接性:プラセボ比較しかなく、実臨床での代替治療との比較がない
- アウトカムの非直接性:サロゲートアウトカム(血圧、HbA1c、腫瘍縮小率など)しか測定されていない
Guyatt 2023のサロゲート議論
Guyatt 2023 [U17] は、「患者にとって重要なアウトカム」と「サロゲート」を区別する判定質問を提示:
→ Noならサロゲート(酸素化、生理指標、心拍出量など)
→ Yesなら患者重要アウトカム(死亡、QOL、呼吸困難感など)
近年の進展:Indirectness Algorithm
2025年にBMJ Core GRADEシリーズの補遺として、非直接性評価のアルゴリズム/フローチャートが発表されました(Guyatt LinkedIn投稿)。読み手としても「どう判定されたか」を追跡可能になりました。
不確実性(Imprecision)
CI の上限と下限の両方が同じ臨床判断を支持するなら精度は十分。どちらかが「効果ありなし」の閾値をまたぐなら確実性を 1 段下げ、両端ともまたぐなら 2 段下げる候補になります。加えて、最適情報サイズ(OIS)に達していないメタアナリシスは、統計的有意でもランダム誤差の影響が残ります。
詳細は JAMA UG Ch23 ページ(2 節「結果の精度を評価する」)。
判定の基本原則
- 点推定値と95% CIを見る
- CIの両端がMIDを超えているか(同じ判断になるか)を確認
- どちらか一方でもMIDをまたいで反対側に行く → Imprecisionで確実性を下げる
- サンプルサイズが小さい/イベント数が少ない → 追加要因
パターン別判定
Pattern A:絶対差 30/1000 (95% CI 25-40) → CIの下限25>MID → Imprecisionなし
Pattern B:絶対差 30/1000 (95% CI 10-60) → 下限10<MID → Imprecision(1段下げ)
Pattern C:絶対差 10/1000 (95% CI -5〜+25) → 不利益側にもまたぐ → 重大なImprecision(2段下げの可能性)
サンプルサイズの目安(OIS)
GRADEでは Optimal Information Size(OIS)という概念を用い、メタ解析の総参加者数が十分かを判定します。目安として、臨床試験のパワー計算に必要な数(通常400-2000人、イベント300前後)を下回るとImprecisionで下げることが多い。
Dissemination bias(情報発信バイアス)
検出方法
- ファネルプロット:点対称か(左右非対称なら疑わしい)
- Egger検定 / Begg検定:非対称性の統計検定
- 登録試験の未発表チェック:ClinicalTrials.govで該当研究の未発表を確認
- 研究数が少ない場合、検定そのものの信頼性が低い点に注意
読み手としての対応
- ファネルプロットが対称 → 一定の安心材料
- 非対称 → 効果は過大評価の可能性、確実性を1段下げる
- 業界資金の試験が多い → Dissemination biasの追加リスク
非RCT・観察研究のSR(GRADE Guidance 44)
GRADE Guidance 44の4ステップ
- 各研究デザインの確実性を個別評価(RCT単独、非RCT単独)
- 効果の整合性を評価:RCTと非RCTの絶対効果差がMID閾値以内か
- ドメイン別判断:RoB、交絡、整合性を個別に検討
- 提示方法の決定:別々に提示/並列行/1つに統合するか
観察研究の典型的な限界
- 交絡:測定/未測定の交絡因子により真の因果効果が歪む
- 選択バイアス:参加者・曝露群・対照群の選択基準の違い
- 情報バイアス:曝露・アウトカムの測定誤差
観察研究が格上げされる3条件
通常「低」から出発する観察研究でも、以下の条件を満たせば確実性を1-2段上げる:
- 大きな効果量(RR >2 or <0.5)
- 用量反応関係が明確
- 残存交絡がすべて逆方向(観察される効果を弱める方向)
例:喫煙と肺がんの関連はRR >10で観察研究ベースでも確実性は高い。
読み手としてのチェック
📌 観察研究SRを読むとき
- ROBINS-I/ROBINS-Eで評価されているか(AMSTAR 2 Q9相当)
- 傾向スコアマッチング・操作変数など交絡対策の記述があるか
- 感度分析で結果が変わらないか
- RCTエビデンスが別にあれば、両者の効果量の整合性を議論しているか [G2]
定性的研究のSR — GRADE-CERQual
CERQualの4評価要素
- 方法論的限界(Methodological limitations):個別研究の質
- 整合性(Coherence):データと解釈の整合性
- データの十分性(Adequacy of data):データの豊富さ・深さ
- 関連性(Relevance):レビューの文脈への適合
なぜ読み手に重要か
推奨を患者に適用するには、患者の価値観と嗜好(Ch21)を理解する必要があります。CERQualで評価された定性的SRは、その基礎情報を提供します。例:「抗凝固療法における患者の価値観のSR」は治療選択肢の提示方法を変えます(Guyatt LinkedIn #45)。
単一推定値がない場合・GPS・ネットベネフィット
Good Practice Statement(GPS)
GPS [G4] の適用条件:
- 利益が明らかで、代替案が非倫理的・非合理
- 正式なエビデンスレビューが不要と判断される
- 例:「手洗い」「患者の同意を得る」「情報提供する」
濫用の兆候:GPSが推奨の半数以上を占める/SRで容易に評価できる質問にGPSを使っている → GRADE評価の回避の可能性。
単一推定値が統合できない場合(Murad 2017)
[G6] はナラティブ統合でも確実性を評価する方法を示しています:
- 効果の方向が一致するか
- 効果量の範囲がMID以内か
- 各研究のバイアスリスク
- 結果の堅牢性
ネットベネフィット分析
ネットベネフィットの手順 2019 は、複数のアウトカムを統合した意思決定枠組み。利益の加重和と害の加重和を引き算する形式で、個別化された推奨を可能にします。Guyatt LinkedInでも推奨("evidence-based decision-analytical approach")。
信頼できるCPGの6つの質問
インタラクティブ・チェックリスト
以下のチェックリストで、目の前のCPGを評価できます。ガイドラインを1つ思い浮かべて各質問に回答してください:
6質問の理論的背景
Guyatt 2023 [U17] の6質問は、以下のUsers' Guidesシリーズを統合したものです:
- [U1] Hayward 1995「CPGの推奨は妥当か?」 → Q1-Q5に相当
- [U2] Wilson 1995「推奨はあなたの患者ケアに役立つか?」 → Ch20 Applicabilityに相当
- [U16] Brignardello-Petersen 2021「CPG推奨の解釈と利用」 → 総合枠組み
判定後の行動
🎯 判定後のアクション
- 信頼できる → Ch20で「自分の患者に適用できるか」を検討
- 部分的に信頼 → 該当する弱点を補完する別ソース(別CPG、最新SR)を参照
- 信頼できない → 別のCPG(GRADE採用・Minds・Cochraneなど)を優先
CPG品質の実例 — NCCN/IOM/日本のCPG問題
素晴らしい診療ガイドラインあら探しシリーズ 特別編+論文+No.1〜16(YouTube/note/論文/docswell/X)— タップで展開
NCCN — GRADE非採用の代表例
NCCN Clinical Practice Guidelines in Oncology(米国)は、GRADEを採用せず独自のEvidence Blocksを用いるため、6質問で以下の問題点が指摘されます [C2]:
- Q4(最新のSR):厳格なシステマティックレビューの実施が明記されず、「GOBSAT(good old boys sitting around a table)」型の可能性
- Q5(推奨強度と確実性の整合):Evidence Blocksは専門家経験に大きく依存し、再現性に限界
- Q3(患者重要アウトカム):コスト考慮と患者中心意思決定の要素が欠落との分析
- Q6(COI):個々のパネリストの評価結果が公開されない
ただし、NCCNは詳細な治療アルゴリズムを提供しており、実臨床で有用な面もあります。完全に参照しないのではなく、6質問で限界を認識した上で利用するのが読み手としての対応。
IOM(米国医学研究所、現NAM)8基準 — 2011
Institute of Medicine「Clinical Practice Guidelines We Can Trust」[C3]:
- 透明性の確保
- COIの管理
- 多職種パネルとステークホルダー参加
- システマティックレビューに基づく
- 推奨の根拠と強さの明記
- 外部レビュー
- 更新のメカニズム
- 実施支援資源の提供
IOM基準はGuyatt 2023の6質問の土台となった歴史的文書です。
日本のCPG問題
日本のCPGは一部で以下の課題が指摘されています [C4]:
- GRADE採用が徐々に進んでいるが未採用のCPGも多い
- COI管理ポリシーは明文化されているが、個別推奨への影響評価が弱いCPGがある
- 更新頻度・Living Guideline化が限定的
- 患者代表のパネル参加が限定的
信頼できる日本のCPG代表例:Minds掲載CPGの一部(GRADE採用)。
AMSTAR 2 — SRの方法論的質を評価する16項目
インタラクティブ評価ツール
重要項目(★)の背景
- Q2 プロトコル事前登録:結果を見てからの分析変更を防ぐ
- Q4 包括的文献検索:少なくとも2つ以上のDB+灰色文献+試験登録
- Q7 除外研究リスト:選択バイアスの透明化
- Q9 個別研究のRoB:RoB 2 / ROBINS-I/E
- Q11 適切な統計統合:異質性への対応、適切なモデル
- Q13 結果解釈でのRoB考慮:感度分析・バイアス方向の議論
- Q15 Dissemination bias評価:ファネルプロット等
評価結果の解釈
| 評価 | 意味 |
|---|---|
| High | 重要項目の欠陥なし、非重要項目は0-1個 → 信頼できる |
| Moderate | 重要項目の欠陥なし、非重要項目の欠陥が複数 → 概ね信頼 |
| Low | 重要項目の欠陥1つ → 限定的に参考 |
| Critically Low | 重要項目の欠陥2つ以上 → 信頼不可 |
PRISMA 2020 — SR報告の透明性 27項目
- AMSTAR 2(16項目):この SR の「方法論的な質」は信頼できるか?
- PRISMA 2020(27項目):この SR は「十分に報告されている」か?
- JAMA UG Ch22 チェックリスト(8 質問):結果を信じてよい水準かを、臨床家の視点で短時間に判定する
JAMA UG は「質問を自分に投げかけながら論文を読む」使い方を想定しており、AMSTAR 2/PRISMA と補完関係にあります。要約は Ch22 ページ を参照。
AMSTAR 2 vs PRISMA 2020
| AMSTAR 2 | PRISMA 2020 | |
|---|---|---|
| 目的 | SRの方法論的質評価 | SRの報告の透明性 |
| 項目数 | 16 | 27 |
| 使う場面 | SRを使うときの批判的吟味 | SRを書くとき/査読するとき |
| 読み手として | このSRは信頼できるか? | このSRは十分に報告されているか? |
27項目の主要セクション
- タイトル・抄録(2項目)
- 緒言(2項目:根拠、目的)
- 方法(12項目:適格基準、情報源、検索、選択、データ抽出、アウトカム、個別研究RoB、効果量、統合、Dissemination bias、確実性)
- 結果(7項目:選択、研究特性、個別研究RoB、効果、統合、Dissemination bias、確実性)
- 考察(4項目:結果の解釈、限界、結論、資金源・COI)
読み手としての使い方
📌 PRISMA 2020を読み手として活用
- PRISMAチェックリスト付録があるSRは、報告が構造化されている可能性が高い
- 特に重要:方法の4番(情報源)、9番(データ抽出)、13番(統合の方法)、22-24番(確実性・Dissemination bias・限界)
- フローダイアグラム(研究選択の流れ)が掲載されているか
公式サイト:prisma-statement.org
推奨を目の前の患者にどう適用するか
JAMA UG Ch23 は、SR の結果を自分の患者に使うとき、ベースラインリスクに応じて絶対効果を計算し直すことを強調しています。同じ RR でも、高リスク患者と低リスク患者では NNT が大きく変わり、ベネフィット/ハームのバランスが逆転することもあります。
計算の流れ・例示は Ch23 要約ページ の「ベースラインリスク」節を参照。
Applicability評価の4次元
- 対象患者の類似性:研究対象と自分の患者の類似度(年齢・重症度・併存症)
- 介入の実行可能性:自施設で実施できるか、代替手段の有無
- リスクのベースライン:自分の患者はCPG想定集団より高/低リスクか
- 価値観の類似性:患者がアウトカムにどう重み付けするか
Guyatt 2023のApplicability事例
例2:同GLは「すべての脳卒中患者をStroke Unitで学際チームで治療」を強く推奨。低所得国の地方救急室ではチームが存在せず適用不可能。→ 現実的な代替策を検討。
ベースラインリスクの重要性
患者のリスクが高い/低いと、同じ相対効果でも絶対ベネフィットが変わります(Ch6)。例:
- 血栓塞栓症低リスク患者への抗凝固薬 → 出血リスクの方が重大
- 血栓塞栓症高リスク患者への抗凝固薬 → ベネフィットが害を上回る
CPGが複数リスク層での絶対効果を提示していれば、自分の患者のリスク層を選択できます。
読み手のチェックリスト
📌 Applicability 7チェック
- 対象集団が自分の患者と合致するか
- 介入が自施設で実施可能か
- 患者のリスク層が想定内か
- 併存症・薬剤相互作用は考慮されているか
- 医療費・アクセスの障壁は
- 患者の価値観に合うか
- 文化的・社会的要因
共同意思決定(SDM)と価値観・嗜好
JAMA UG は推奨の強さを 4 パターンに整理しています。強/条件付き × 推奨/反対 の組み合わせで、患者との対話の密度が変わります。
「just do it」レベル。SDM はエビデンスの要約を簡潔に伝える。
SDM が必須。ベネフィット/ハーム/価値観を一緒に検討。
SDM で、患者が重視するアウトカム次第では実施を検討。
ハームが明らかで、実施しない旨を伝える。
条件付き推奨(中央の 2 パターン)は、「推奨をどう使うか」よりも「どう患者に説明するか」が焦点になります。
SDMの3ステップ
- Choice talk:選択肢があることを患者に伝える
- Option talk:各選択肢の利益・害・確実性を具体的に説明
- Decision talk:患者の価値観・状況を確認し、共に決定
価値観と嗜好のエビデンス
患者の価値観も研究可能です。例:
- 抗血栓療法における患者価値観のSR [V2]:48件の研究を系統的に統合。「脳卒中回避 vs 出血リスク」の重み付けに関する集団レベルの傾向を提示。
- 質的SR(CERQual評価、Ch14):患者体験を系統的に要約。
これらは集団レベルの価値観であり、個別患者の価値観はSDMで確認する必要があります。
条件付き推奨での対話例
対話例:
「このお薬は年間の脳卒中リスクを5%から2%に下げますが、出血リスクを0.5%から1.5%に上げます。脳卒中を避けることを強く重視される方には推奨できます。出血の懸念が強い方は別の選択肢もあります。あなたはどのように考えますか?」
強い推奨でのSDM
Guyatt 2023 [U17] は、強い推奨でも理論的にはSDMを行うべきだが、時間制約から実践的には限定的と認めています。ただし患者の強い反対意思があれば聞き入れる姿勢は必要です。
用語集 + Q&A
主要用語
Q&A(よくある質問)
Q1. GRADEの「低い確実性」の推奨は無視してよいですか?
A. いいえ。低い確実性でも、現在利用可能な最良のエビデンスです。確実性が低い場合は①代替案がより良いか検討②SDMで患者の価値観を重視③フォローアップで効果を確認、などの対応をします。
Q2. CPGが複数あって推奨が食い違う場合は?
A. Ch16の6質問でそれぞれのCPGを評価し、より信頼できる方を優先してください。方法論が同等なら、自国・自施設の文脈に近い方を優先。
Q3. RCTがない領域(希少疾患など)ではどうすれば?
A. 観察研究のSR(Ch13)、定性的研究のSR(Ch14)、単一推定値がない場合(Ch15)の各手法を組み合わせて判断。MAGIC・希少疾患CPGの取り組みが参考になります。
Q4. 英語のCPGを読むのが難しいです
A. まずは SoF表(Ch5)のみに絞って読む → 徐々に推奨本文とEtD → 最後にメタ解析詳細、という段階的アプローチがおすすめ。また、日本語の信頼できるCPG(Minds、Cochrane日本語訳)から始めるのも有効。
最新情報 + Guyatt先生 LinkedIn ピックアップ
参考文献一覧
- U1 Hayward RS, Wilson MC, Tunis SR, Bass EB, Guyatt G. Users' guides VIII. How to use clinical practice guidelines. A. Are the recommendations valid? JAMA 1995;274(7):570-574.
- U2 Wilson MC, Hayward RS, Tunis SR, Bass EB, Guyatt G. Users' guides VIII. B. What are the recommendations and will they help you in caring for your patients? JAMA 1995;274(20):1630-1632.
- U3 Dans AL, Dans LF, Guyatt GH, Richardson S. Users' guides XIV. How to decide on the applicability of clinical trial results to your patient. JAMA 1998;279(7):545-549.
- U4 Barratt A, et al. (EBM Working Group). Users' guides XVII. Screening. JAMA 1999;281(21):2029-2034.
- U5 Guyatt GH, Sinclair J, Cook DJ, Glasziou P. Users' guides XVI. How to use a treatment recommendation. JAMA 1999;281(19):1836-1843.
- U6 McAlister FA, Straus SE, Guyatt GH, Haynes RB. Users' guides XX. Integrating research evidence with the care of the individual patient. JAMA 2000;283(21):2829-2836.
- U7 Attia J, et al. (incl. Guyatt). How to use an article about genetic association: B & C. JAMA 2009;301(2):191-197 / 301(3):304-308.
- U8 Fan E, Laupacis A, Pronovost PJ, Guyatt GH, Needham DM. How to use an article about quality improvement. JAMA 2010;304(20):2279-2287.
- U9 Mills EJ, et al. (incl. Guyatt). How to use an article reporting a multiple treatment comparison meta-analysis. JAMA 2012;308(12):1246-1253.
- U10 Mulla SM, Scott IA, Jackevicius CA, You JJ, Guyatt GH. How to use a noninferiority trial. JAMA 2012;308(24):2605-2611.
- U11 Andrews J, Guyatt G, Oxman AD, et al. GRADE guidelines: 14. Going from evidence to recommendations. J Clin Epidemiol 2013;66(7):719-725.
- U12 Murad MH, Montori VM, Ioannidis JPA, et al. (incl. Guyatt). How to read a systematic review and meta-analysis and apply the results to patient care: users' guides. JAMA 2014;312(2):171-179. PMID 25005654
- U13 Neumann I, Santesso N, Akl EA, et al. (incl. Guyatt). A guide for health professionals to interpret and use recommendations in guidelines developed with the GRADE approach. J Clin Epidemiol 2016;72:45-55. PMID 26772609
- U14 Agoritsas T, et al. (incl. Guyatt). UpToDate adherence to GRADE criteria for strong recommendations. BMJ Open 2017;7(11):e018593.
- U15 Liu Y, Chen PC, Krause J, Peng L. How to read articles that use machine learning. JAMA 2019;322(18):1806-1816.
- U16 Brignardello-Petersen R, Carrasco-Labra A, Guyatt GH. How to Interpret and Use a Clinical Practice Guideline or Recommendation. JAMA 2021;326(15):1516-1523. PMID 34665198
- U17 Lima JP, Mirza RD, Guyatt GH. How to recognize a trustworthy clinical practice guideline. J Anesth Analg Crit Care 2023;3:9. DOI
- U18 Guyatt G, Rennie D, Meade MO, Cook DJ (eds.). Users' Guides to the Medical Literature: A Manual for Evidence-Based Clinical Practice, 3rd ed. McGraw-Hill Education; 2015.
- M1 Jaeschke R, Singer J, Guyatt GH. Measurement of health status. Ascertaining the minimal clinically important difference. Control Clin Trials 1989;10(4):407-415. (MCID原典)
- M2 GRADE Guidance 42(閾値設定). J Clin Epidemiol 2024.
- M3 Yao X, et al. GRADE note 6. 2025.
- M4 2024閾値論文群. J Clin Epidemiol.
- M5 絶対リスク差のための論文. 2023.
- M6 些細・中・大の閾値を使っているCPG例. 2025.
- M7 Evaluating the credibility of anchor based estimates of minimal important differences for patient reported outcomes. BMJ Medicine 2025.
- G1 Djulbegovic B, Guyatt GH. Progress in evidence-based medicine: a quarter century on. Lancet 2017;390(10092):415-423.
- G2 Cuello-Garcia CA, et al. GRADE guidance 44: Strategies to enhance the utilization of randomized and non-randomized studies in evidence syntheses. J Clin Epidemiol 2025.
- G3 Lewin S, et al. Applying GRADE-CERQual to qualitative evidence synthesis findings. Implement Sci 2018;13(Suppl 1):2.
- G4 Guyatt GH, et al. Guideline panels should seldom make good practice statements. J Clin Epidemiol 2015.
- G5 Piggott T, et al. Standardized wording to improve efficiency and clarity of GRADE EtD frameworks in health guidelines. J Clin Epidemiol 2022;146:106-122.
- G6 Murad MH, et al. Rating the certainty in evidence in the absence of a single estimate of effect. Evid Based Med 2017;22(3):85-87.
- G7 観察研究ROB — ROBINS-E / ROBINS-I / ネットベネフィット 2019 / GRADE Guidance 45 NAM. 各種.
- T1 Shea BJ, Reeves BC, Wells G, et al. AMSTAR 2: a critical appraisal tool for systematic reviews. BMJ 2017;358:j4008. amstar.ca
- T2 Page MJ, McKenzie JE, Bossuyt PM, et al. The PRISMA 2020 statement. BMJ 2021;372:n71. prisma-statement.org
- C1 = U17 Lima-Mirza-Guyatt 2023(再掲)
- C2 NCCNガイドラインの批判的吟味 — NCCNのEvidence Blocksに関する分析
- C3 Institute of Medicine. Clinical Practice Guidelines We Can Trust. National Academies Press; 2011.
- C4 日本のCPG問題 — 日本国内CPGの方法論的課題の分析
- V1 患者の価値観と嗜好を利用(日英両版) — EtDへの組込み方法
- V2 Patient values and preferences in antithrombotic therapy: SR. ACCP Guidelines(LinkedIn #45で紹介)
- L1 Gordon Guyatt's LinkedIn activity. linkedin.com/in/guyattgh/recent-activity/all/
EBM・システマティックレビュー・診療ガイドラインの関係
🎯 なぜ、この解説を最初に読むのか?
本サイトの本体(Ch1〜Ch24)は、「すでにEBM・SR・CPGの定義を理解している人」が、診療ガイドラインやシステマティックレビューを「読みこなす」ために書かれています。しかし、実際には多くの医療者が以下のような誤解を抱えたまま診療情報を利用しています:
- ❌ 「システマティックレビューならエビデンスレベルが高い」
- ❌ 「ランチョンセミナーで有名な先生が"EBMに基づく"と言ったから信頼できる」
- ❌ 「診療ガイドラインなのだから、どれを選んでも大差ない」
- ❌ 「AIがPubMedを検索してまとめてくれるから、それで十分」
こうした誤解が放置されると、患者に不利益を与える判断が日常的に起こり得ます。本ページでは、先生ご自身が作成されたキースライド(16枚)に沿って、EBM・SR・CPG の定義とその"なぜ"、そして信頼できる医療情報を見極める目の養い方を解説します。
1. 医学情報の信頼性 — あなたはどちらを信頼する?

ポイントは「ほぼ」という言葉です。医療において、1000人に1人でも誤った情報で不利益を被る患者が出れば、それは許容できません。AIは補助ツールとして有用ですが、最終的な信頼性の判断は、方法論を理解した人間にしかできないことを、まず認識してください。
2. 「知っている」「使っている」ではダメな理由

- 「EBM? 知っているよ」 → 5ステップは言える。でも3つの基本原則は?
- 「システマティックレビュー? 読んだことあるよ」 → では、なぜ系統的検索が必要か、説明できますか?
- 「診療ガイドライン? 使っているよ」 → その CPG の推奨の強さの根拠、把握していますか?
これらの「なぜ」が答えられないまま臨床情報を使うと、都合の良い情報だけを無意識に選んでしまい、結果として患者に最適でない医療を提供することになります。以下、1つずつ紐解いていきましょう。
3. EBMの定義 — Sackett 1996

「根拠に基づく医療(EBM)とは、個々の患者のケアに関する意思決定において、現在得られる最良の根拠を、良心的に・明示的に・思慮深く用いることである。」
この定義のキーワードは3つ:「良心的(conscientious)」「明示的(explicit)」「思慮深く(judicious)」。これらは後で学ぶ透明性・再現性・価値観の統合に直結します。
4. EBMの5ステップ(Evidence cycle: 5つのA)
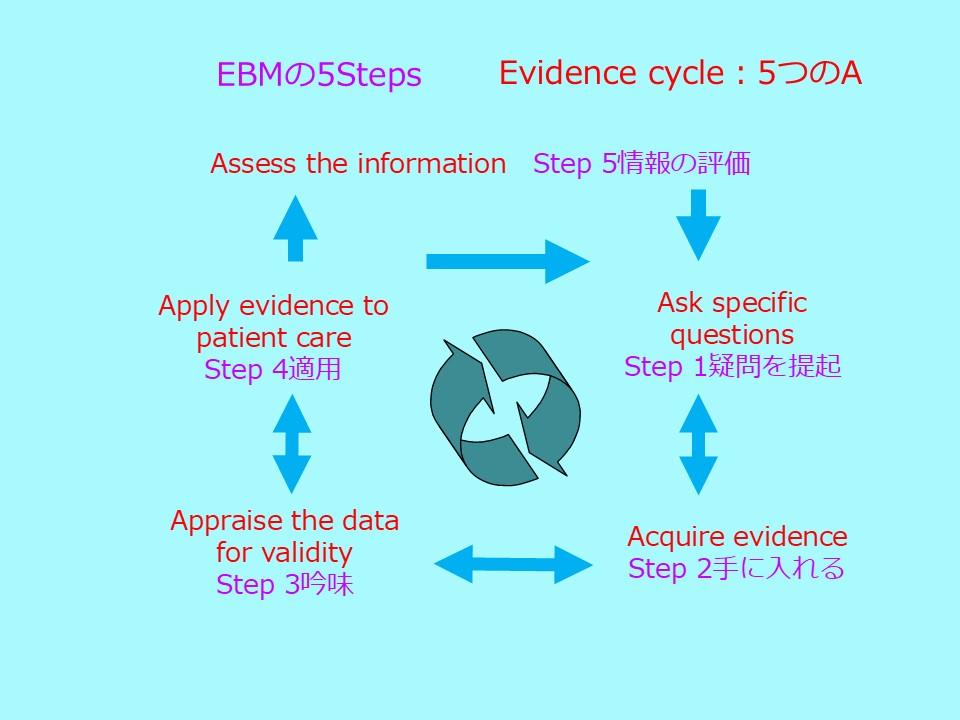
5ステップは多くの医療者が知っています。しかし、「5ステップさえ回していれば EBM」と誤解している人が大半です。本当に重要なのは、次に説明する3つの基本原則です。
5. ⭐ EBMの3つの基本原則(意外に知られていない)


🎓 この原則から導かれる、実践上の重要ポイント
- EBMにおける検索は効率重視。まずSR、なければ非RCT・症例報告も活用。
- 信頼性の評価はチェックシートで迅速に行えばよい(全てを精読する必要はない)。
- SRを検索するならPubMedで直接。AIよりハルシネーションがなく確実。
- 近年は信頼できる CPG が増えたため、SRの前に CPG を参照することも多い(ただし信頼できない CPG にも注意)。
6. 診療ガイドライン(CPG)の世界的定義

「診療ガイドラインとは、システマティックレビューによって得られたエビデンスと、代替的なケア選択肢の利益と害の評価に基づいて、患者ケアを最適化することを意図した推奨を含む記述である。」
この定義には3つの必須要素が含まれます:
(a) システマティックレビュー、(b) 利益と害の評価、(c) 推奨。
この3要素のいずれかが欠落している文書は、世界標準の「診療ガイドライン」ではありません。残念ながら日本国内の学会作成CPGには、定義を満たしていないものも少なくありません [U17][C4]。
7. システマティックレビュー(SR)の定義
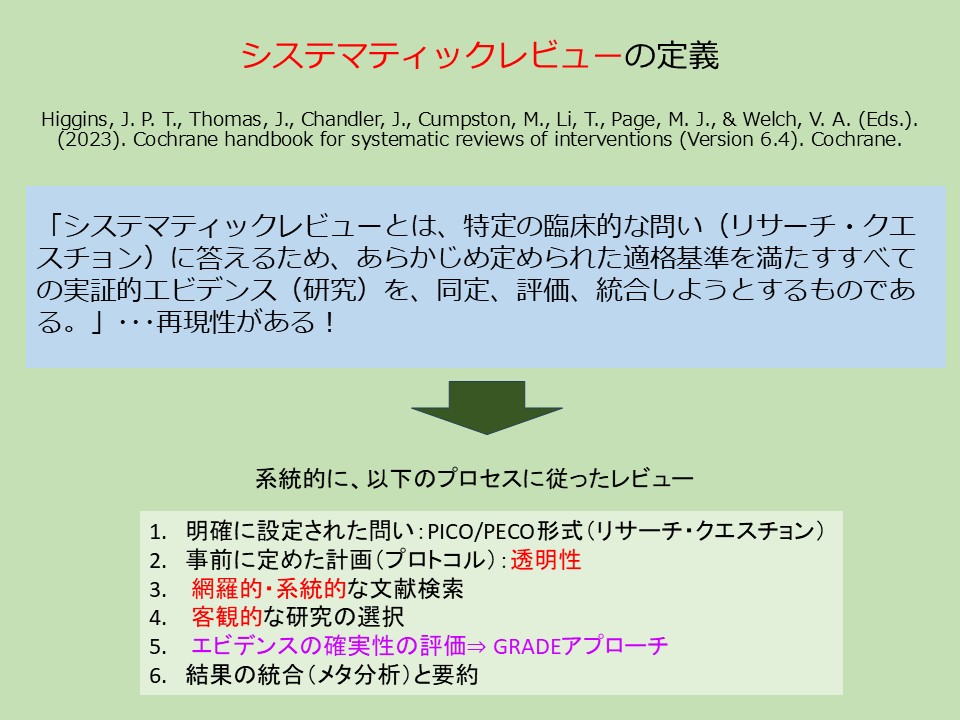
「システマティックレビューとは、特定の臨床的な問い(リサーチ・クエスチョン)に答えるため、あらかじめ定められた適格基準を満たすすべての実証的エビデンス(研究)を、同定・評価・統合しようとするものである。」…再現性がある!
SRが従うべき6ステップ
- 明確に設定された問い:PICO/PECO形式
- 事前に定めた計画(プロトコル):透明性
- 網羅的・系統的な文献検索
- 客観的な研究の選択
- エビデンスの確実性の評価 ⇒ GRADEアプローチ
- 結果の統合(メタ分析)と要約
8. ⭐⭐ エビデンスの確実性とは — 同じ"1.62"でも確実性は違う
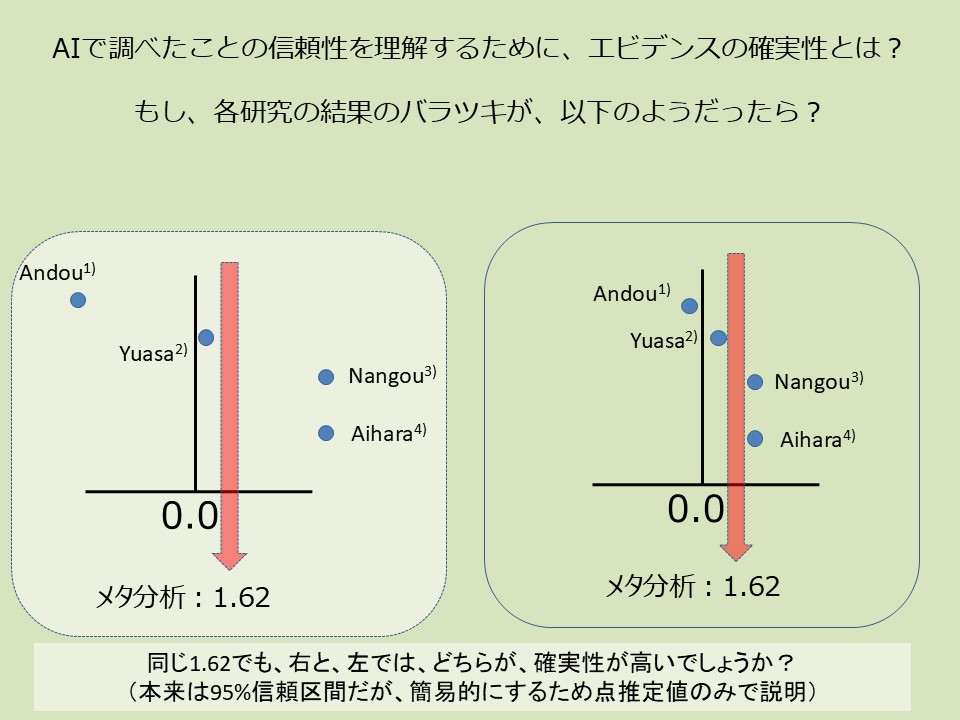
左右の図は、いずれも4つの研究を統合したメタ分析の結果 1.62 を示しています。しかし、研究結果のバラツキが全く違います。
4つの研究結果が大きく分散 → メタ分析の 1.62 は偶然の産物かもしれない → 確実性 低
4つの研究結果がほぼ一致 → メタ分析の 1.62 は本当に 1.62 に近い → 確実性 高
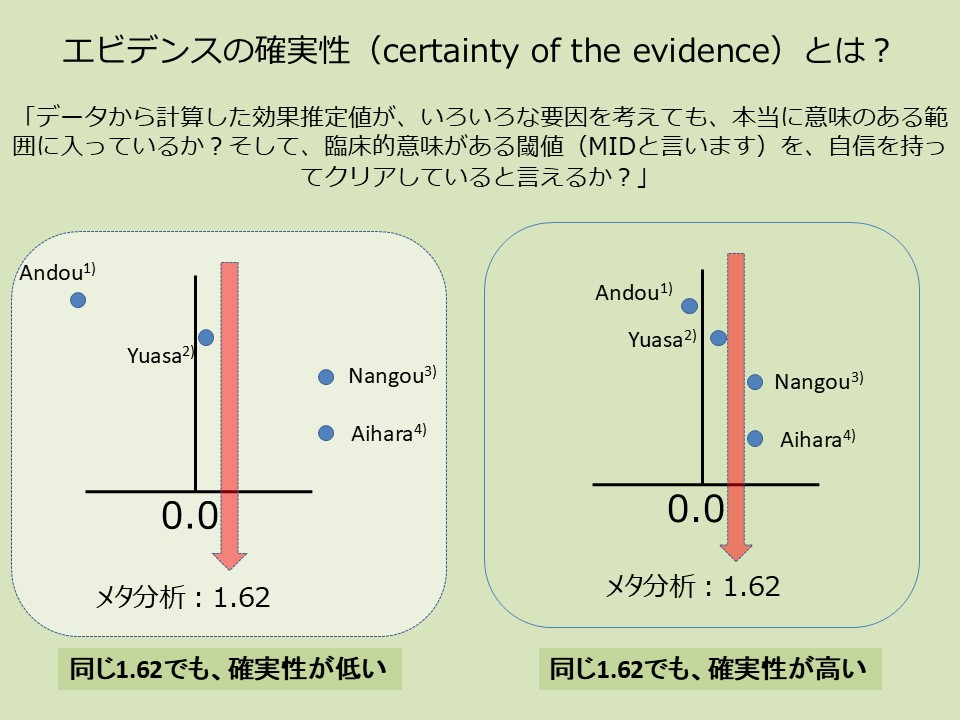
9. エビデンスの確実性を下げる5要因(GRADEアプローチ)
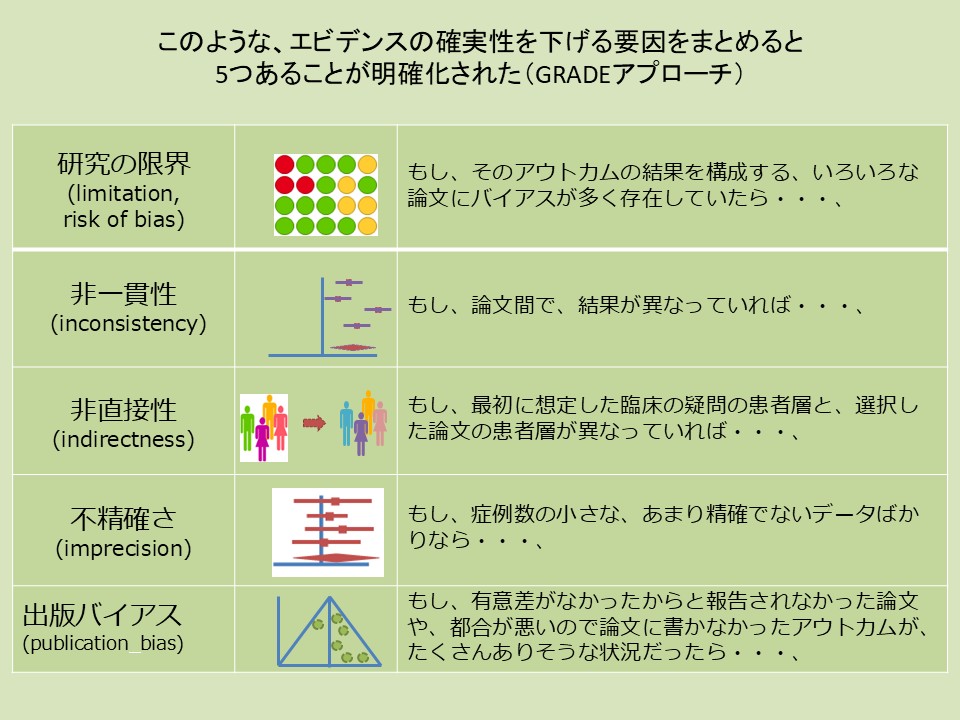
そのアウトカムの結果を構成する論文にバイアスが多く存在していたら…
論文間で結果が異なっていれば…
最初に想定した臨床の疑問の患者層と、選択した論文の患者層が異なっていれば…
症例数の小さな、あまり精確でないデータばかりなら…
有意差がなかったからと報告されなかった論文が、たくさんありそうな状況だったら…
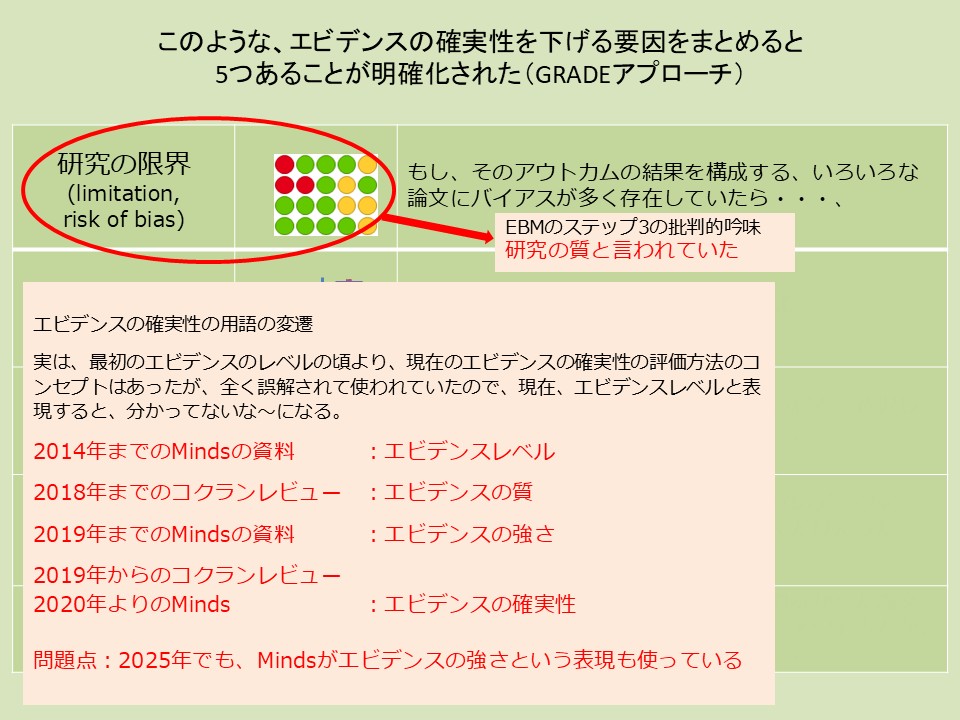
10. ⭐⭐⭐ 最重要:SRの質と、エビデンスの確実性は別物
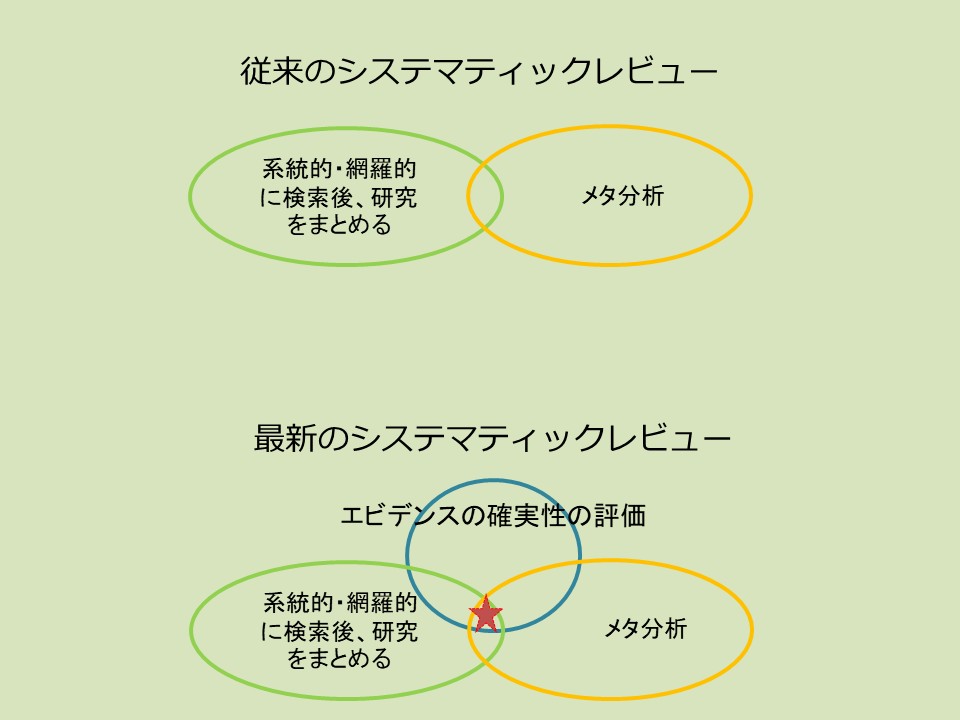
従来のSRは「系統的・網羅的に検索」+「メタ分析」の2輪だけでした。しかし最新のSRは、そこに必ず「エビデンスの確実性の評価」が加わります(図の★印)。メタ分析ができない定性的SRでも、確実性の評価は必須です。

11. 診療ガイドラインの解説文 — 批判的吟味の実例

問題:SR1はRCT1・RCT2を含んでいるはず。なのに並列で並べるのは重複カウント。どのRCTが含まれているか不明、SRの質・エビデンスの確実性も不明。
問題:各SRで使われているRCTが異なるのか同一なのか、SRが丁寧に作られているのか、メタ分析結果のエビデンスの確実性も何も分からない。
このような解説文は、CPG としての信頼性を大きく損ないます。本サイトの Ch16(信頼できる CPG の6つの質問)・Ch18(AMSTAR 2)で、こうした CPG・SR を系統的に判定する方法を学びます。
13. 🆕 Guyatt先生のCore GRADE — 「GRADEが複雑になりすぎた」という反省
Core GRADE の7論文シリーズ(BMJ 2025)
💡 Core GRADE の設計思想(先生の言葉)
- 複雑で高度な方法論ほど"上級"ではない。本当に重要なのは、誰でも使えるシンプルさ。
- "guidance, not rules" — Core GRADE はルールではなく判断の指針を提供する。
- "Close-call decisions are common" — 境界線上の判断は頻繁にある。絶対的な答えを求めない柔軟性が必要。
- 公式GRADEの追加ガイダンスはあっていい — しかし、それがなくてもCoreで誤った判断には至らない、というのが重要。
14. 🆕 確実性評価の「ターゲット」選択 — Null vs MID
以前の GRADE では、確実性は「点推定値(point estimate)」に対するものと定義されていましたが、Core GRADE では「ある閾値のどちら側に真実があるか」の確信度として再定義されました(Zeng et al. 2021)。
閾値は2つだけ — Null と MID
読み手が "効果があるか/ないか" だけに関心がある場合。
読み手が "患者に実際に意味のある大きさの効果か" を知りたい場合。
ターゲット選択の4ステップ(Guyatt 2025年講演より)
- 閾値を選ぶ — Null か MID か。
- 点推定値の位置を見る — 閾値のどちら側にあるか。
- 点推定値が真実なら、どんなメッセージになる? — それが確実性評価のターゲットになる。
- 信頼区間が閾値を跨ぐか見る — 跨いでいれば不精確性(imprecision)で1段階ダウングレード。Core GRADEはこれだけで済ませる。
・ターゲットをNullにした場合:点推定値は0.82(利益側)→「有益な効果がある」という確信度。信頼区間が1を跨ぐ → 1段階ダウン。
・ターゲットをMID(たとえば0.90)にした場合:点推定値は0.82(MIDより大きな利益)→「臨床的に重要な利益がある」という確信度。信頼区間がMIDを跨ぐ → 1段階ダウン。
💡 ターゲットの使い分け(Guyatt先生のアドバイス)
- 読み手によって両方のターゲットで評価を提示することも可能(パネルが高度に情報リテラシーのある読者向けに評価する場合)。
- 両方を跨いだり近かったりする場合は、境界判断を"educated thoughtful gestalt"(熟慮された総合判断)に委ねるのが正しい。
- 「ターゲットがMIDで、点推定値がMIDよりも小さい場合、"重要な効果はない"という確信度を評価する」— これは一見混乱しやすいが、Core GRADE の重要なロジック。
15. 🆕 最適情報サイズ(OIS) — 少数症例で大きな効果は要注意
Guyatt 先生らが BMJ 2025 で強調しているのは、「エビデンス蓄積の初期に大きな効果が見られる研究が、後続研究で追試されないケースが多い」という経験則です。例えば、ある薬で相対リスク減少が60%以上という大効果が、少数症例研究で示されても、症例数が積み上がると効果は縮小していくことが頻繁に起こる。
OIS の計算
- α(有意水準の許容限界):通常 0.05
- β(検出力の許容限界):通常 0.20(検出力 80%)
- コントロール群のイベント発生率:臨床コンテキストから設定
- 控えめな相対リスク減少:通常 20% または 25%(控えめに設定するのがミソ)
ここから計算される症例数が OIS(Optimal Information Size)。
ダウングレードの判定
16. 🆕 「Risk of Bias」は「Bias」ではない — 教育的ゲシュタルトの原則
具体例で理解する
Core GRADE の新アプローチ — 2段階評価
(例:盲検化されていた/いなかった)
(アウトカムとの関係・文脈を考慮)
複数研究を統合する際の判断フロー(ROBUST-RCT)
→ Yes なら通常ダウングレード
→ Yes ならダウングレードしない
→ 一致している:RoBは実際の影響を及ぼしていないと推定 → ダウングレードしない
→ 一致していない:高RoB研究を除外し、低RoBのみで解析 → ダウングレードしない
💡 教育的ゲシュタルトの原則(Guyatt 2025)
- 「GRADE の最終評価は、その基準を満たすかどうかの機械的判定ではなく、熟慮された総合判断(educated thoughtful gestalt)によるべき」— Core GRADE の根本原則。
- GRADE の評価者の直感が「確実性はもっと低い」と感じるなら、恐らく評価者の直感が正しい。機械的ルールの盲信は誤り。
- これは「ルールを曲げろ」という意味ではなく、"GRADE のロジックを理解した上で、文脈に即した判断を下す"ということ。
17. 🆕 サブグループと背景リスク — 「誰に推奨するか」の科学
2つの異なる概念
例:COVID-19 の死亡リスクは、免疫抑制患者で高い。パクスロビドの RR=0.5 は同じでも、絶対効果は免疫抑制群で大きい。
頻度:非常に多い。年齢・重症度・併存疾患などは、ほぼ常に背景リスクに影響する。
例:薬が若年層では RR=0.5 だが高齢層では RR=0.8。
頻度:非常にまれ。本当に RR が異なるには、強い生物学的根拠が必要。
Guyatt先生が提案する判定基準(2025年Q&A)
⚠️ "どちらに行くか分からない"仮説は棄却する。事前に方向を言えない仮説は、post-hoc の fishing に堕する。
💡 パクスロビドの例(WHO ガイドライン 2022、Guyatt参加)
- 背景リスクの高い集団(相対効果は同じ、絶対効果が大きい):免疫抑制患者、血清陰性、未ワクチン
- 相対効果が大きい可能性のある集団(要事前仮説):症状発現からの時間が短い、血清陰性、未ワクチン
- → WHO ガイドラインでは「非重症COVIDの高リスク患者にはパクスロビドを条件付きで推奨、低リスク患者には推奨しない」という集団別の推奨へ
18. 🆕 エビデンスから推奨へ — 4つの推奨タイプと「強さ」の決定
推奨の2×2グリッド
個別患者視点:3つの主要要因
集団視点:追加される4つの要因
「確実性の低いエビデンスで強い推奨」を出すには、正当な例外理由(生命を脅かす状況、代替手段なし、害が極小等)を明示する必要がある。
19. 🆕 Guyatt先生Q&A — 実践現場の難問と回答
以下は、Guyatt 先生の Clarity Research FAQ と 2025年12月講演から、日本の臨床家に特に有用な Q&A を抜粋・要約したものです。各質問はタップで展開されます。
単一RCTしかない場合、Cochraneは必ずGRADE評価を要求する。過剰評価になるのでは?
レビューを計画した以上、誰かがその介入を使おうとしているということです。そうなら、最良の効果推定値とその確実性が提供されるべきです。それは研究数に関わらず当てはまります。
重要なのは、確実性評価を正しくすること。あなたの直感が「これは low か very low だ」と告げるなら、GRADE 機械的判定で過剰評価している場合はそれを修正すべき。
- 点推定値が大きく、OISを満たさない → 不精確性で2段階ダウンが可能
- OISからさらに大きく不足 → 3段階ダウンも妥当
- 出版バイアスの懸念(単一研究でも理論的にあり得る) → 追加ダウン可
- RoB 懸念があれば追加ダウン可
結果として very low certainty の評価に至れば、それが正しい評価。
背景リスクとサブグループ効果、同じ因子(例:未ワクチン)は両方に該当するか?
はい、同じ因子が両方に該当することはあります。プロセスとしては別々に検討すべきです:
- 背景リスク:その特性で "悪いアウトカムのリスク" が違うなら含める。これは よくある(年齢・重症度・併存疾患など)。
- サブグループ効果:その特性で "相対効果" が違う 明確な生物学的理由 があるなら含める。これは まれ。
- COVIDの未ワクチンは両方に該当し得る:ベースライン死亡率が高く、かつ治療の相対効果も大きい可能性。
鉄則:「どちらに行くか分からない」仮説は棄却する。事前に方向を言えない仮説はpost-hoc になる。
2つの大規模RCTでメタ分析、RR=0.88(95%CI 0.75-1.13、N=2950)。不精確性でダウングレードは何段階?
まず、ターゲットを決めることが第一ステップ。
Nullをターゲットにした場合:
- 点推定値=0.88は利益側 → 「非ゼロの利益」が評価のターゲット
- 信頼区間が1を跨ぐ → 最低1段階ダウン
- 1段階か2段階かは「probably effective」と伝えるか「possibly effective」と伝えるかの判断
- 13%のRR増加(害の可能性)もある → "probably"と言うのは躊躇する → 他にダウン要因がなければ 2段階ダウンが妥当
ただし、最終的にはゲシュタルトで総合判断:他ドメインでダウン済みなら、ここで2段階ダウンするとvery lowになってしまう。その場合は1段階ダウンに留めて low とする方が適切。
MIDはどう決めるのか?プロトコル段階で決めるべきか?
理想的にはプロトコル段階で決定する。しかし実際には柔軟性がある:
- ガイドラインパネルが組成されてから、パネルが自分たちのMIDを指定する場合がある → その後SRの確実性評価を修正
- SRチームが最初はNullでだけ評価し、パネルがMIDを決めた後で追加のMID評価を行う
患者報告アウトカム(PRO)はMIDのエビデンスが豊富だが、有害事象などは研究が少ないため、パネル内の患者・臨床専門家のコンセンサスに依存することが多い。
Core GRADEと公式GRADE(Full GRADE)で、最終的な確実性評価は変わるか?
正式な比較研究はまだ行っていませんが、Core GRADE を設計する際の前提は「高度な方法論を加えても、最終的な確実性評価や推奨の方向・強さに重要な差を生じさせない」ということ。
細かい方法論的工夫(境界線上の判断への高度な対処など)は、"methodologically sophisticated" で面白いが、incremental benefit is not crucial。Core GRADE は「本質」を定義することに特化している。
MAGIC Foundation・BMJ Rapid Recommendations・WHOのCOVIDガイドラインは、何年も Core GRADE で運用されている。
高RoBの研究は、感度分析で除外すべきか、本解析から完全に除外すべきか?
完全に除外すべき。理由:
- 低RoB研究だけで解析 → 高い確実性が得られる
- 高RoBを混ぜる → 結果をぼかし、バイアスを導入する可能性 → なぜ混ぜるのか?
- 高RoBと低RoBで結果が異なる → RoBが実際に影響している証拠 → 高RoBは除外
- 高RoBと低RoBで結果が似ている → RoBは実害なかったと推定 → 全て使って確実性をダウングレードしない
GRADEproとMAGICapp、どちらを推奨?
先生ご自身は「ソフトウェア懐疑派」で、手作業でGRADE評価を行う。ただし、MAGIC Evidence Ecosystem Foundation の MAGICapp のボードメンバーであり、特にガイドライン作成には GRADEpro より MAGICapp を推奨している(バイアスあり、と自己申告)。
ただし、ソフトウェアは方法論の本質的判断にはあまり役立たない。方法論の議論をする際に、ソフトウェアの挙動に頼るべきではない。
12. まとめ — 信頼できる医療情報を見極める目を養うために

🎯 患者にとって望ましい情報を考えると…
- 最新の情報が欲しい
- 偏ってない情報が欲しい
- 信頼性が高い情報が欲しい
- 研究段階でなく、臨床で使える情報が欲しい
→ 信頼できる診療ガイドライン、なければ、自分で信頼できる情報を探す
信頼できる情報を探すために:
- 患者も AI で調べる時代で、同じレベルではプロではない
- ハルシネーションは「ゼロ」でなければならない
- エビデンスの確実性の評価が自分でできなければならない(AI では不可能)
- もっとも、AI は有用であり、利用すべきである
- 医学以外の分野では、AI、特に Deep Research が有用
本サイトの Ch1〜Ch24 は、このための最短ルートです。
📍 次のステップ:本サイトのどこから読むか
🗺️ 本サイトの学習ロードマップ(Primer読了後)
JAMA Users' Guides to the Medical Literature(第3版)第22章の枠組みを、独立の解説として整理しました。この章の目的は「SR/MAというプロセスが、私たちが結論を信じてよい水準で実施されたか」を見抜く視点を持つことです。本編の各章(Ch1, Ch8〜12, Ch18, Ch20)と補完的に読むと理解が深まります。
心臓手術以外の大手術を控えた高リスク患者について、周術期のβ遮断薬perioperative β-blockerを投与すべきか迷っています。過去のガイドラインは「投与を推奨」としていた時期がありましたが、大規模RCT(POISE)以降、推奨は揺れ動いてきました。最新のSR/MAを探し、本当に信じてよいのか自分で判断したい — これが出発点です。
1. なぜ SR/MA を探すのか — ナラティブレビューとの違い
臨床上の疑問に答えるには、1本のRCTだけでなく、関連するすべての研究を系統的・再現可能な手順で集めて統合する必要があります。JAMA UG は SR と従来の「総説(ナラティブレビュー)」の違いを次のように整理しています。
用語整理
- システマティックレビュー SR:焦点を絞った臨床疑問を、再現可能な方法で統合する研究のタイプ。
- メタアナリシス MA:SR のなかで、個別研究の結果を統計的に統合して単一の推定値(point estimate)と信頼区間(CI)を算出する工程。統計的統合を行わない SR も正当(統合不可能な場合、ナラティブ統合に留める)。
2. SR/MA の標準プロセス — 9 ステップの俯瞰
JAMA UG が示す標準的な実施プロセスは以下の流れです。読者としては、論文本文および PRISMA 図でこの流れが追えるかを確認します。
- 疑問を定式化する(PICO/PECO)患者・介入・対照・アウトカムを明示的に定義
- 適格基準を決める研究デザイン・対象集団・介入の範囲・アウトカム
- 異質性を説明する事前仮説サブグループ解析の方向性を事前に明文化
- 系統的な文献検索MEDLINE / EMBASE / Cochrane Central を最低限カバーし、検索語・期間・言語制限を明記
- タイトル・抄録・全文のスクリーニング独立した 2 名以上で行い、κ統計量で一致度を評価
- バイアスのリスク評価とデータ抽出これも独立した 2 名以上で実施
- 効果推定値の統合(MA を行う場合)固定効果/変量効果モデルを適切に選択
- 異質性の評価I²・Q 検定・事前仮説に基づくサブグループ解析
- 確実性(エビデンスの質)の評価と報告GRADE による格付けと Summary of Findings の提示
3. SR/MA の信頼性を見抜く 8 つの質問
JAMA UG は、臨床家が SR/MA を批判的に読むためのチェックリストとして、次の質問を提示します。本書では各質問の要点を解説付きで示します。
- 臨床的に意味のある疑問が明確に設定されているかP・I・C・O が絞られていて、臨床現場で遭遇する問いと一致するか
- 検索は徹底かつ系統的か複数データベース(MEDLINE / EMBASE / Cochrane Central)に加え、未公表データ・試験登録・引用追跡・専門家照会まで確認したか
- 研究の選択と評価は再現可能か独立した 2 名によるスクリーニング、κ統計量による一致度の報告
- 1 次研究のバイアスリスクが適切に評価されたかランダム化・隠蔽化・盲検化・追跡・ITT などの主要ドメインを、個別研究ごとに判定しているか
- 研究間の結果のばらつき(異質性)の理由が探られているかI²・視覚的評価・事前仮説に基づくサブグループ解析/メタ回帰
- 効果推定値の確実性(エビデンスの質)が等級付けされているかGRADE に沿った評価が提示され、アウトカムごとに理由が明記されているか
- 報告バイアスが検討されているかファンネルプロット、trim-and-fill、未公表研究の統合など
- 自分の患者に適用できる結果が提示されているかベースラインリスク別の絶対効果、NNT、重要なサブグループでの効果
4. 各質問の要点 — 読むときの着眼点
Q1 — 疑問は明確か(PICO の定式化)
レビューの冒頭で、対象患者の範囲(年齢・病期・重症度・併存症)、比較される介入、対照、臨床的に重要なアウトカムが具体的に列挙されていることを確認します。
⚠️ 注意:「良いSRほど焦点は絞られ、適格基準は厳格」だが、その反面 一般化可能性は狭くなる というトレードオフがあります。あなたの目の前の患者がその範囲に入るかを必ず照合します。
Q2 — 検索は徹底的か
単一データベースだけの検索は不十分。最低 3 つの国際データベース(MEDLINE / EMBASE / Cochrane Central)に加え、以下をチェック:
- 学会抄録・会議録
- 試験登録(ClinicalTrials.gov, WHO ICTRP)
- 引用追跡(参考文献リストのチェック)
- 専門家への照会・灰色文献
- FDA/EMA の申請資料(薬剤の場合)
FDA 資料と公表論文を比べると、未公表試験や結果の歪んだ報告が見つかる例があります(報告バイアス/選択的アウトカム報告)。
Q3 — 選択と評価は再現可能か(κ統計量)
スクリーニングとバイアスリスク評価は、独立した 2 名以上で行う必要があります。食い違いが出るのは当たり前で、それをどう解決したか(3 人目の裁定、議論)まで報告されるのが望ましい形です。
一致度はκ統計量kappaで定量化され、0.6 以上(実質的一致)が目安。κの報告がない SR は、選択バイアスの懸念が残ります。
Q4 — 1次研究のバイアスリスク評価
RCT では以下のドメインを個別研究ごとに判定:
- ランダム化の方法(配列生成)
- 割り付けの隠蔽化(concealment)
- 盲検化(患者・医療者・評価者・解析者)
- 脱落/追跡不能の影響
- ITT 原則の適用
- 早期中止(stopped early for benefit)
⚠️ 客観的アウトカム(死亡)では盲検化の影響は小さいが、主観的アウトカム(疼痛・QOL)では盲検化の破綻がバイアスを大きく増やすため、アウトカムごとに影響を考えます。
詳細は Ch8 Risk of Bias を参照。
Q5 — 異質性の理由は探られているか
統合する前に、個別研究の結果が互いに近いか(一貫しているか)を必ず確認します。評価方法は:
- 視覚的評価:フォレストプロット上の点推定値のばらつきと CI の重なり
- Q 検定(yes/no 式の帰無仮説検定)
- I²統計量:ばらつきのうち研究間差が占める割合を % で示す(0–100%)
ばらつきが大きい場合は、事前に計画されたサブグループ解析/メタ回帰でその源を説明すべきです(患者特性・介入量・追跡期間・研究の質など)。事後的に無理やり説明するのは「仮説を生み出す」程度の信頼性しかありません。
詳細は Ch9 不一致性 を参照。
Q6 — エビデンスの確実性(質)の等級付け
JAMA UG の標準は GRADE。RCT は「高」、観察研究は「低」を出発点とし、以下の要因で上下します:
バイアスのリスク/非一貫性(inconsistency)/非直接性(indirectness)/不精確性(imprecision)/出版バイアス
大きな効果量/用量反応性/交絡要因が効果を減弱させる方向に働く
結果は 高・中・低・非常に低 の 4 段階で示されます(Ch3)。
Q7 — 報告バイアスは検討されているか
JAMA UG は報告バイアスへの対処として 4 つの手法を挙げます:
- 小規模研究と大規模研究で結果が異なるかを比べる
- ファンネルプロットの視覚的検討(対称性)
- 点推定値のばらつきの非対称性を定式化した統計検定(Egger など)
- 統計的有意差の欠落した研究の過多を検出する方法
⚠️ いずれの手法も完璧ではなく、研究数が少ない SR では検出力が低いことに注意。最善の対処は「最初からすべての研究が登録・報告される仕組み」を社会として作ることです。
Q8 — 自分の患者に適用できる結果か
レビューが「相対リスク(RR)」だけを示しているなら半分の仕事です。臨床家には絶対効果が要ります。ベースラインリスク別に絶対リスク差・NNT を提示してこそ、目の前の患者に使える情報です。
例:相対リスク 25% 減 (RR 0.75) は
- 高リスク患者(年間イベント率 8%)→ 絶対差 2%/NNT = 50
- 低リスク患者(年間イベント率 0.5%)→ 絶対差 0.125%/NNT = 800
同じ RR でも臨床的意味は全く違う。この視点は Ch6 相対 vs 絶対 と Ch20 患者への適用 が詳しい。
5. フォレストプロットの読み方 — 模式図
JAMA UG は SR/MA のフォレストプロットを「結果を要約する言語」と位置づけます。次のような読み方をします。
- 四角の大きさ = 研究の重み(精度 = サンプルサイズと情報量)
- 横線 = 95% 信頼区間(CI)
- ダイヤモンド = 統合推定値と CI
- 縦線(無効線 RR = 1 または RD = 0)を CI がまたぐと「統計的有意差なし」
- 結果のばらつきを目で見て、どれくらい似ているかを第一印象で判断するのが異質性評価の出発点
β遮断薬のSR を読んで、上記 8 項目に照合します。
Q1–Q3:検索範囲・独立レビューが明記されていれば合格。
Q4:POISE 試験のような大規模・低バイアス試験が含まれているか。少数の古い試験のみなら信頼度は低い。
Q5:心血管アウトカム(ベネフィット)と脳卒中・死亡(ハーム)の両方でサブグループ解析がされているか。
Q6:GRADE による確実性が、主要アウトカムごとに示されているか。
Q8:あなたの目の前の患者のベースラインリスクに当てはめた NNT/NNH が提示されているか。
この 8 項目をクリアして初めて、「SR/MAの結果を信じてよい」水準に達します。信じられる SR が得られたら、次は Ch23(結果の理解と適用) へ進み、効果の大きさ・精度・患者への適用可能性を評価します。
Ch22 で「信じてよい SR/MA」を見分けました。次は、その結果を目の前の患者にどう当てはめるかです。JAMA UG 第23章は、効果の大きさ・精度・確実性・適用可能性を段階的に評価する枠組みを提示します。
非心臓手術を受ける 66 歳男性、2 型糖尿病・高血圧 を担当します。最新の SR/MA(周術期 β 遮断薬の影響)を読み、この患者に投与すべきかを判断したい — 効果推定値の数値から、NNT・NNH まで自分で計算できるようになるのが目標です。
1. 効果の大きさ — どう表現されるか
SR/MA の要約推定値は、アウトカムのタイプに応じて異なる指標で示されます。
 🔍 タップで原寸表示・スマホはピンチで拡大
🔍 タップで原寸表示・スマホはピンチで拡大
| アウトカムのタイプ | よく使われる指標 | 解釈の要点 |
|---|---|---|
| 2 値(発生/非発生) 死亡・心筋梗塞など |
相対リスク RR/オッズ比 OR/リスク差 RD/相対リスク減少 RRR | RR=0.75 → 介入でイベントが 25% 相対的に減少。絶対効果に変換すると臨床的意味が見える。 |
| 発生までの時間 生存解析 |
ハザード比 HR | HR=0.80 → 単位時間あたりのイベント発生率が 20% 低い。 |
| 診断検査の精度 | 尤度比 LR(正・負) | LR+ が 10 以上 / LR− が 0.1 以下で、事後確率を大きく動かす。 |
| 連続変数 BP・QOLスコア |
加重平均差 WMD/標準化平均差 SMD | 異なるスケールを統合する場合は SMD。解釈には MID(最小重要差)を参照。 |
SMD(効果量)は「何 SD 分だけ改善したか」という抽象的な単位です。臨床家に伝わる形にするには、代表的な尺度(例:6 分間歩行距離、Chronic Respiratory Questionnaire)の実単位に戻し翻訳(back-translation)します。
2. 結果の精度を評価する — 信頼区間と不精確性
効果推定値(点推定値)のまわりの不確かさを示すのが信頼区間CIです。JAMA UG は精度の評価を次のように説明しています。
- CI の上限と下限の両方で臨床判断が変わらないなら、精度は十分
- CI のどちらかの端が「重要な効果あり/なし」の境界(閾値)をまたぐなら、不精確性で確実性を 1 段下げる候補
- CI 上下限の両方が閾値をまたぐなら、2 段下げることもある
- 統計的有意 (p<0.05) があっても、CI が広ければ臨床判断は不安定
適切な精度を得るためには、メタアナリシス全体で所定のサンプルサイズ(OISOptimal Information Size)に達している必要があります。症例数が少なく CI が広い場合、統計的有意でも「ランダム誤差で生じた可能性」が残り、確実性を下げる根拠になります。
詳細は Ch11 不確実性 と、Primer(page-25)のセクション15(OIS)も併読。
3. 研究間の結果のばらつき(異質性)を理解する
同じ介入でも、研究によって結果が違うのは普通のことです。JAMA UG は、ばらつきの評価と説明を 3 段階で行います。
- 視覚的評価フォレストプロット上で、点推定値のばらつきと CI の重なりを目視
- 統計的検定Q検定(p 値)、I²統計量(% で表現)
- 臨床的・方法論的な説明事前に計画されたサブグループ解析で、ばらつきの原因を探る
I² の解釈の目安
- 0–40%:重要でない異質性の可能性
- 30–60%:中等度の異質性の可能性
- 50–90%:実質的な異質性の可能性
- 75–100%:かなりの異質性 — 統合の妥当性を慎重に考える
サブグループ解析の信用性 — 5 つの基準
ばらつきを「年齢・重症度・介入量」などのサブグループで説明できたと主張するとき、その主張を信じてよいかは次の 5 点で評価します。
- サブグループ効果の方向は、生物学的・臨床的に妥当か
- その効果は、研究内(within-study)の比較か、それとも研究間(between-study)の比較か → 研究内比較のほうが信頼できる
- 事前に計画された仮説か、事後の探索か → 事前計画のほうが信頼できる
- 検定される仮説の数は少ないか(多重比較の問題)
- 他の独立した研究で再現されているか
4. エビデンスの確実性(質)を等級付けする — GRADE
JAMA UG は、要約推定値の確実性を評価するスタンダードとして GRADE を採用します。本アプリの Ch2〜Ch12 が詳しいので、ここでは JAMA UG 独自の視点をハイライトします。
単一の「GRADE 評価」はない。同じ SR でも「死亡」「脳卒中」「QOL」でそれぞれ確実性は異なり得ます。バイアスのリスク、異質性、不精確性はアウトカムによって異なる影響を受けるためです。
Summary of Findings(SoF)表は、アウトカム行ごとに確実性(高・中・低・非常に低)と理由を示します。詳細は Ch5 SoF 表の読み方 を参照。
5. 結果を自分の患者に直接適用できるか
信頼できる効果推定値が得られても、それを目の前の患者に使ってよいかは別の問題です。JAMA UG は 4 つのチェックポイントを提示します。
- 患者の特性は、研究対象と十分似ているか年齢・性別・併存症・病期・重症度
- 介入の内容は、あなたの環境で実施可能か用量・投与経路・期間・実施チームの技能
- 対照は、あなたの通常診療と比較できるかプラセボ対照 vs 標準治療対照 で解釈が大きく変わる
- 結果は、患者にとって重要か代理アウトカムではなく患者重要アウトカム(death・disability・QOL)か
- 患者:目の前の患者が研究対象からかけ離れていないか
- 介入/対照:実施可能性、用量、通常診療との差
- アウトカム:真のアウトカムか、代理アウトカムか
詳細は Ch10 非直接性 を参照。
6. 絶対効果とベースラインリスク — 臨床で活かす算数
SR/MA は多くの場合相対効果(RR、OR、HR)を主要結果として示します。臨床判断にはベースラインリスク × 相対効果 = 絶対効果への変換が必須です。
計算例 — 周術期 β遮断薬
介入なし群の MI リスク = 5.1%(ベースライン)
RR = 0.73 → 介入群 MI リスク = 5.1 × 0.73 = 3.7%
絶対差 ≈ 1.4% → NNT ≈ 70
(1000 人に 14 人少ない心筋梗塞)
介入なし群の脳卒中リスク = 0.5%
RR = 2.17 → 介入群 = 0.5 × 2.17 = 1.09%
絶対差 ≈ 0.6% → NNH ≈ 170
(1000 人に 6 人多い脳卒中)
ベネフィットとハームのバランスは、絶対効果でみて初めて適切に評価できます。相対効果は「効果の生物学的な大きさ」を示しますが、臨床的な差引きは絶対効果でしか計算できません。
JAMA UG が推奨する優先順位:
- SR 内の対照群(介入なし)の平均リスク
- SR がレビューした観察研究のコホート
- 外部の大規模観察研究/レジストリ
- リスク層別化ツール/予測モデル(Framingham、CHA₂DS₂-VAScなど)
目の前の患者のリスクが平均と違うなら、そのリスクを入れて絶対効果を計算し直すのが正しい使い方です。
7. エビデンスプロファイル — 結果の一覧表
GRADE ワーキンググループが推奨する要約形式がエビデンスプロファイルとSummary of Findings(SoF)表です。患者にとって最も重要なアウトカムを行として、各アウトカムの確実性・絶対効果・相対効果を一望できます。
| アウトカム | 相対効果 | ベースラインリスク | 介入群のリスク | 確実性 |
|---|---|---|---|---|
| 心筋梗塞 | RR 0.73 (0.61–0.88) | 51/1000 | 37/1000 (14 人少ない) |
🟢 高 |
| 脳卒中 | RR 2.17 (1.26–3.74) | 5/1000 | 11/1000 (6 人多い) |
🟢 高 |
| 総死亡 | RR 1.27 (1.01–1.60) | 25/1000 | 32/1000 (7 人多い) |
🟢 高 |
| 低血圧 | RR 1.51 (1.39–1.65) | 100/1000 | 151/1000 (51 人多い) |
🟢 高 |
例示の数値は POISE 試験(Lancet 2008)の再解析およびそのメタアナリシスから報告された値を参考に、教育目的で簡略化して示したもの。
66 歳、糖尿病・高血圧を持つこの患者について、上の SoF 表を適用します。
ベネフィット:MI リスクが年間 5.1% ほどあると仮定 → 1000 人に 14 人少ない MI。
ハーム:脳卒中 +6人、総死亡 +7人、低血圧 +51人/1000人。
確実性:いずれも GRADE「高」。
判断:MI の絶対利益よりも、脳卒中と死亡の絶対害が大きいと判断され、ルーチンの周術期高用量 β 遮断薬はこの患者には推奨しない。もともと β 遮断薬を服用中の患者は継続、という個別判断に落ち着く。
この「ベネフィット − ハーム」を、患者の価値観も含めて一緒に決めるプロセスが Ch21 共同意思決定 です。
直接比較する RCT がない選択肢のあいだで優劣を知りたいとき、ネットワークメタアナリシスNMA / network meta-analysisが使えます。JAMA UG 第24章は、NMA の仕組みと、読者が信頼性を判定するためのチェックポイントを示します。
45 歳女性、片頭痛。これまで市販鎮痛薬では効かず、トリプタン系薬剤のなかでどれが最も効果的かを比較したい。しかし、多くのトリプタンはプラセボ対照の RCT はあるが、薬剤どうしの直接比較 RCT は限定的。NMA で横断的に比較したい。
1. NMA は何が違うか — 従来 MA との対比
「介入 A vs プラセボ」「介入 B vs プラセボ」を別々に統合。A と B を直接比べる RCT がなければ比較できない。
プラセボを共通の比較対象として、A vs プラセボとB vs プラセボの情報を用いて A vs B の間接比較を計算。直接比較があればそれと統合して総合推定値を作る。
2. ネットワークの形 — 典型パターン
JAMA UG は NMA で扱う典型的なネットワーク形状を 4 つのパターンで整理しています。
閉ループ(B)や完全連結(D)のネットワークは、直接比較 vs 間接比較の一貫性をチェックできる点で信頼性が高くなります。
3. NMA の信頼性を判定する — ユーザーズガイド
- 適格基準に明白で適切な臨床疑問が含まれているかPICO が一貫しており、ネットワーク全体の「被験者同士が交換可能」と言える範囲か
- 研究の選択と報告のバイアスリスクが低いか検索の徹底性、出版バイアス、選択的アウトカム報告
- 研究間の違い(異質性)への説明があるか患者集団・介入量・アウトカム測定法の違い
- 直接比較と間接比較の結果が一貫しているか(整合性coherence)閉ループでの一貫性検定、ノード分割(node-splitting)など
- 著者は対比較ごとに確実性を等級付けしているかGRADE は「A vs B」ごとに「高・中・低・非常に低」を付けるべき
- 結果は感度推定や潜在的バイアスに頑健か感度分析、バイアスリスクの低い試験のみでの再解析
- ランク付け(例:SUCRA)の限界が明示されているか「最も有効」の見かけのランクは信頼性が低いことが多い
- 患者にとって重要なアウトカム全てが検討されているか有効性だけでなく、有害事象・QOL も NMA に含まれているか
4. 整合性(coherence)— NMA 特有の概念
同じ比較(A vs B)について、直接比較(A 対 B の RCT)と間接比較(プラセボを経由した計算値)が得られる場合、両者が一致するかを必ず検討します。
- 研究に組み込まれた患者集団の違い(年齢・重症度・疾患の範囲)
- ベースラインリスク・以前の治療歴の違い
- 介入の用量・投与期間・併用療法の違い
- アウトカムの定義や測定時点の違い
- 研究の実施年代による通常診療の進化
5. ランク付けの落とし穴
NMA の結果として介入のランキング(1 位、2 位…)やSUCRA値が提示されることがあります。魅力的に見えますが、JAMA UG は深い落とし穴を指摘しています。
- データが少ない介入は偶然に上位に来ることがある
- 順位は「差が臨床的に意味がある」ことを保証しない
- 確実性の低いエビデンスに基づくランクは、新しい試験で順位が変わる可能性が高い
- 「最も有効」のランクだけを見て、対比較ごとの確実性を見ないのは誤り
6. NMA の結果の適用 — 4 つのチェック
- 患者重要アウトカム全てが検討されているか(有効性+有害事象+QOL)
- 考えうる治療選択肢が全て含まれているか(臨床現場で選びうるすべての介入)
- 想定されているサブグループ効果のうち、信用性の高いものがあるか
- 結果は感度推定や潜在的バイアスに頑健か(非一貫性の有無含む)
片頭痛に対するトリプタン NMA(たとえば Thorlund 2014)は、プラセボ対照・直接比較を含む多数の RCT を統合し、頭痛消失率・2 時間持続効果率・副作用を比較しています。
結果の読み取り:エレトリプタン 40 mg、スマトリプタン 100 mg、リザトリプタン 10 mg が頭痛消失率で上位にランクされますが、対比較ごとの確実性を見ると、上位 3 者間の差は小さく、確実性も「中」程度のことが多い。
臨床判断:ランキング 1 位に飛びつかず、利用可能性・副作用プロファイル・患者の既往歴(冠動脈疾患の有無など)・コスト・過去の反応を総合して選択する。
